Result 6
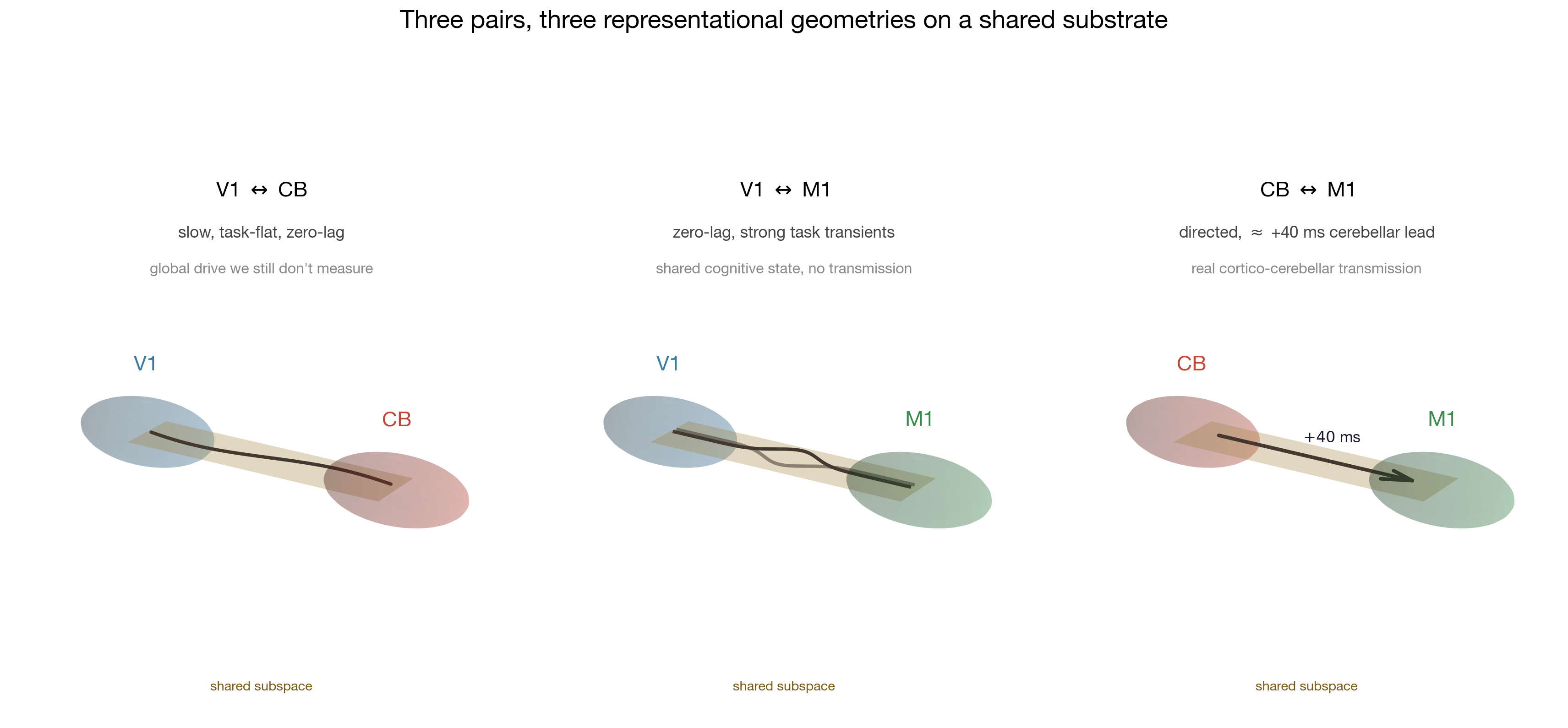
The geometry, made visible
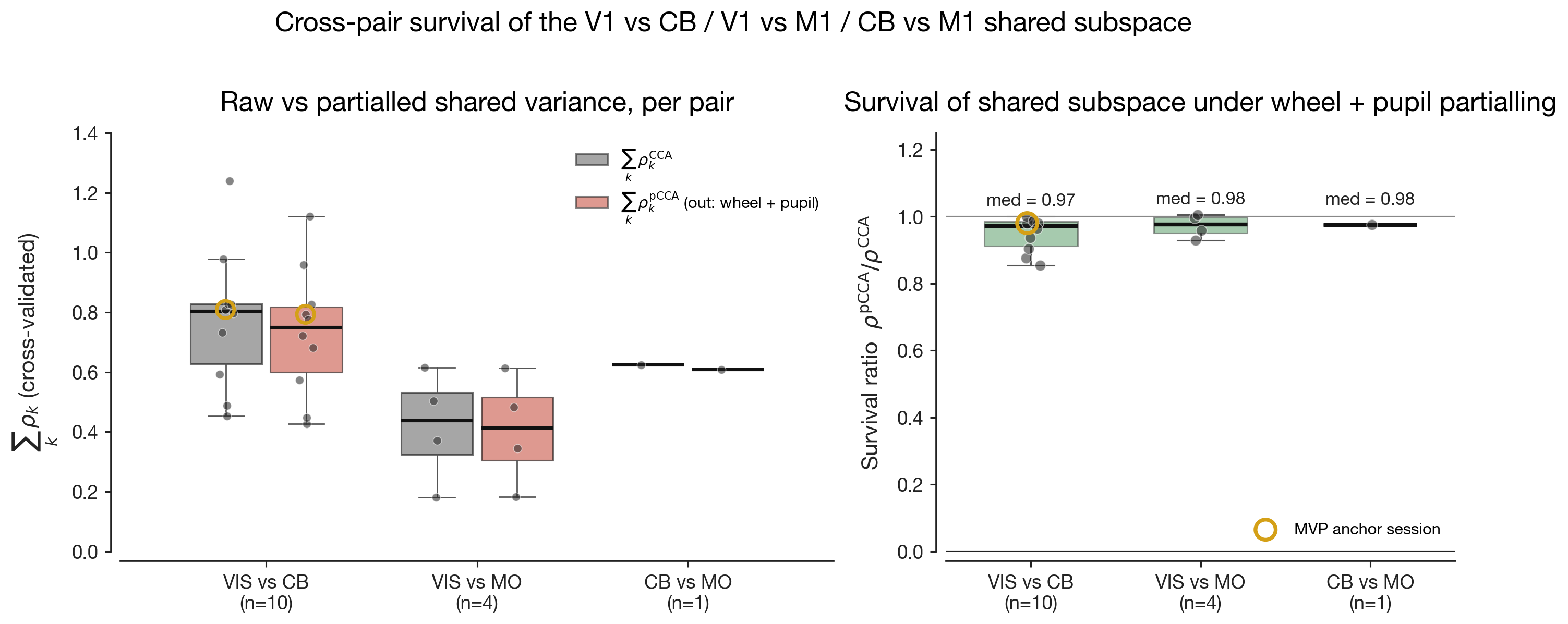
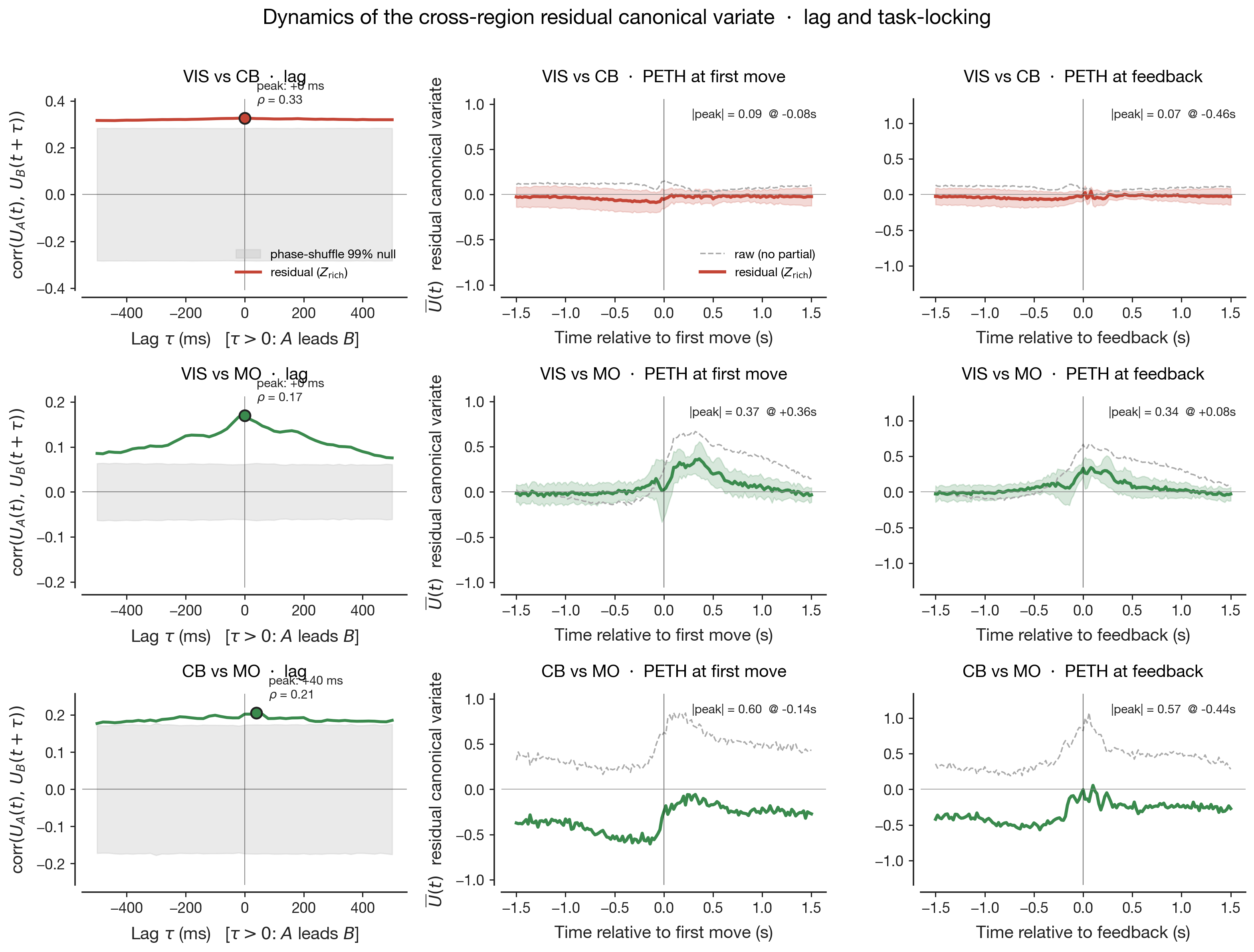
The five preceding results live as scalars: ΔR² distributions, canonical
correlations, survival ratios, lag-of-peak, peri-event amplitude. Numbers
can rank, but they do not let the reader see what the shared
geometry is doing. Two pictures below turn the central claim — three
pairs reach similar survival through different geometric mechanisms —
from a sentence into a shape, and add one piece of information the
scalar analyses cannot give us: the shape persists under partialling, but
what that shape means about behaviour does not.
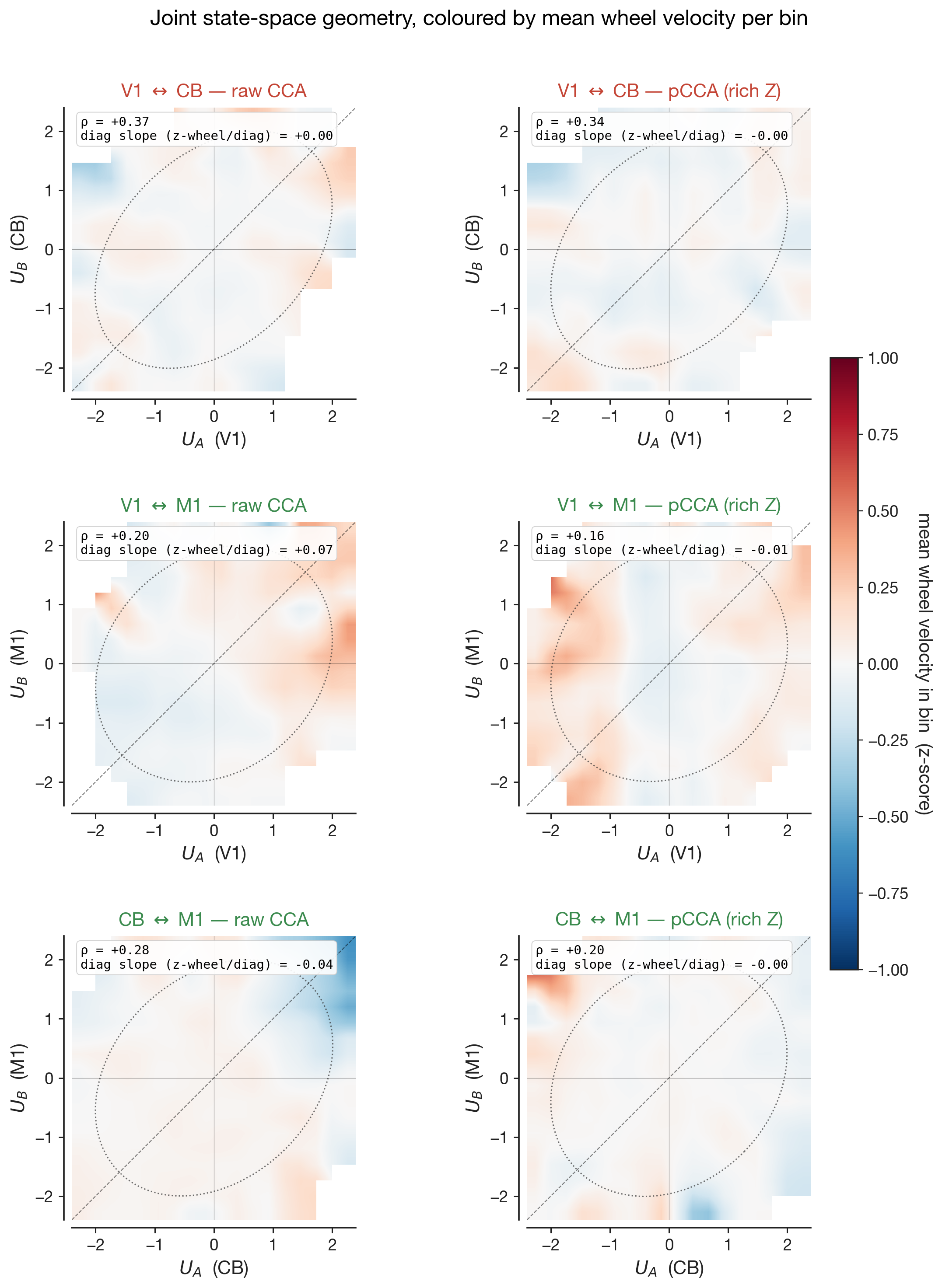
What does the shared mode mean? Joint state-space, coloured by wheel velocity
Canonical correlation gives us a single number — how aligned the two
regions' subspaces are — but it does not tell us what that alignment
is. To see the shared mode itself, we plot the leading
canonical variates of the two regions, $U_A(t)$ and $U_B(t)$, against
each other on a 2-D plane. Each point in this plane is one 20-ms time
bin: $U_A$ is region A's projection of its population activity onto
the leading cross-region axis at that moment; $U_B$ is region B's
projection onto its matched axis. A strong cross-region coupling shows
up as a cloud aligned along the diagonal — when region A's
projection is high, so is region B's. The shape of the
cloud is the geometry of the shared mode.
The shape alone, however, says nothing about what the shared mode is
about. So we colour each pixel of the 2-D histogram by the
mean wheel velocity (z-scored) of the time bins that fall into it. If
the shared mode is, in essence, the running-versus-quiet axis, the
bins on one side of the diagonal will be times when the mouse is
stationary (blue) and the bins on the other side will be times when
the mouse is running (red): the cloud develops a clear blue-to-red
gradient along its long axis. If the shared mode is not primarily
about running, the wheel velocity is distributed indiscriminately
across positions in the cloud and the colour is uniform grey. The
shape tells us whether the geometry survives; the
gradient tells us how much of that geometry was the
wheel axis to begin with.
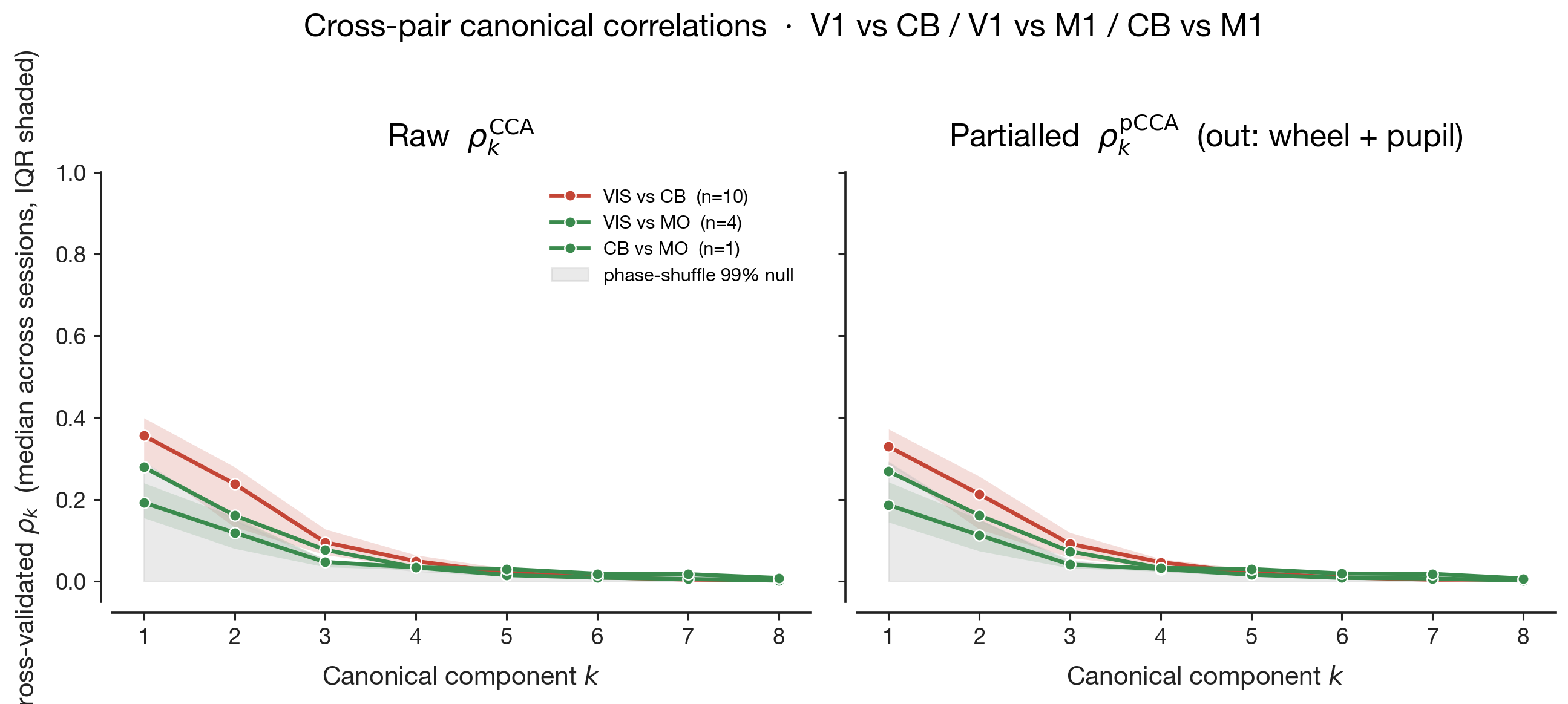
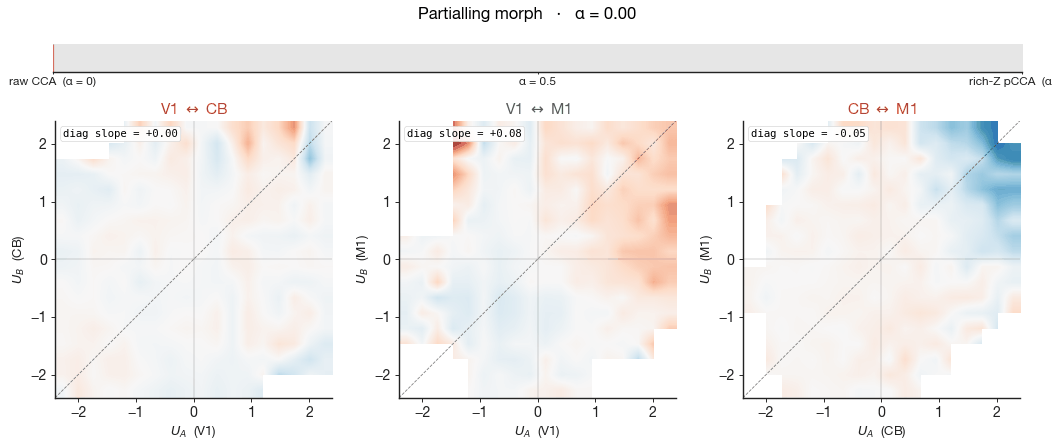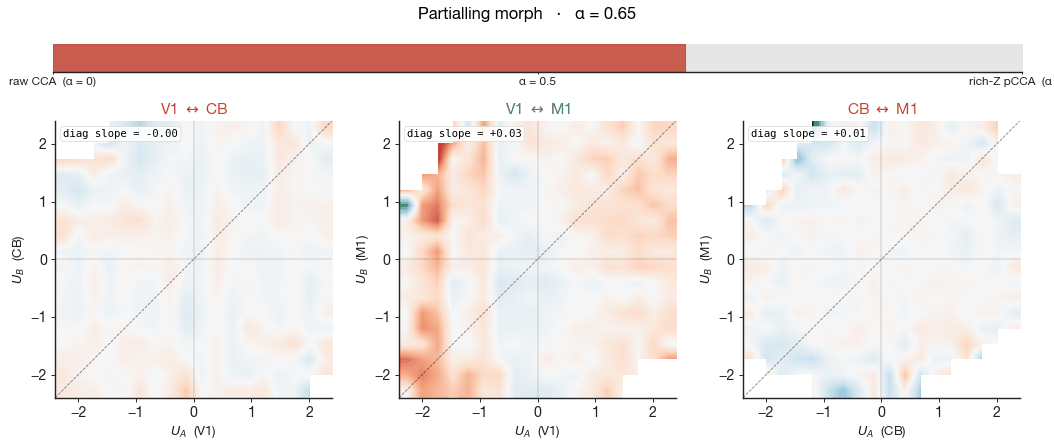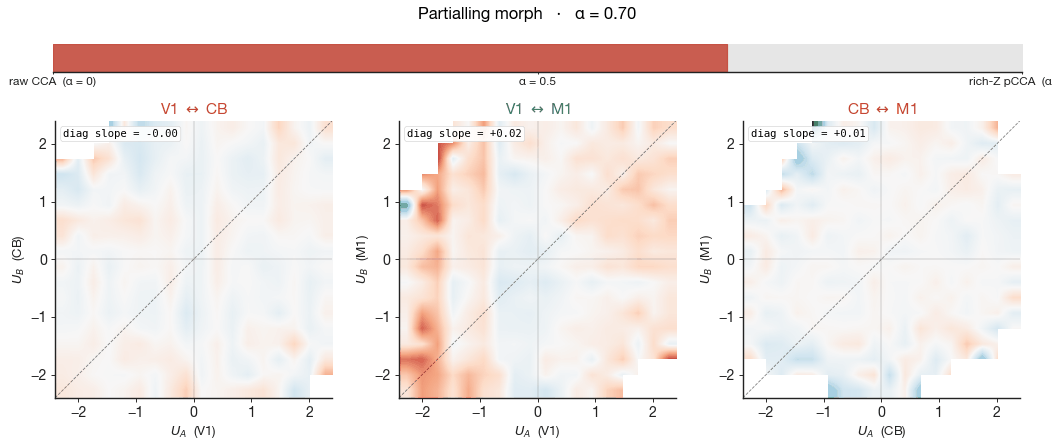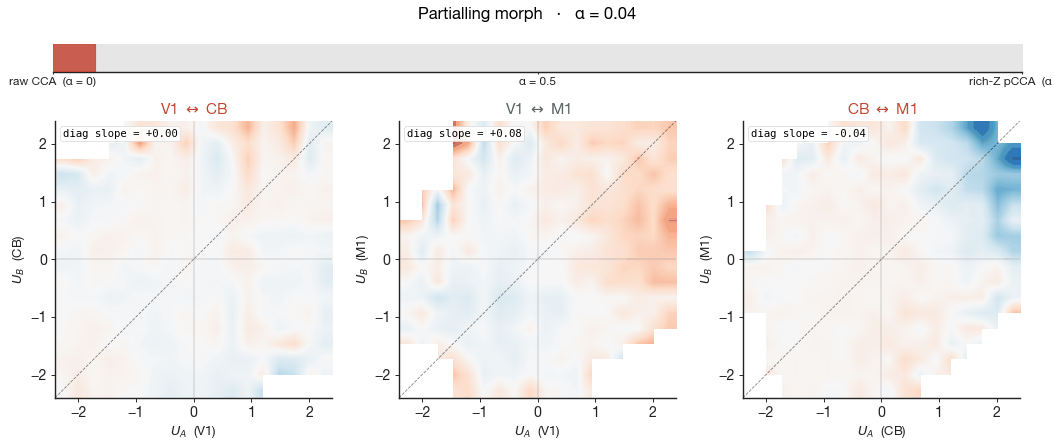
The left column of Figure 7 shows the raw CCA — no behavioural
partialling. All three pairs carry a non-trivial wheel-velocity
gradient: positions along the leading shared canonical axis are
partly diagnostic of how fast the mouse was moving. The signed slope
of this gradient is printed inside each panel as "diag slope". The
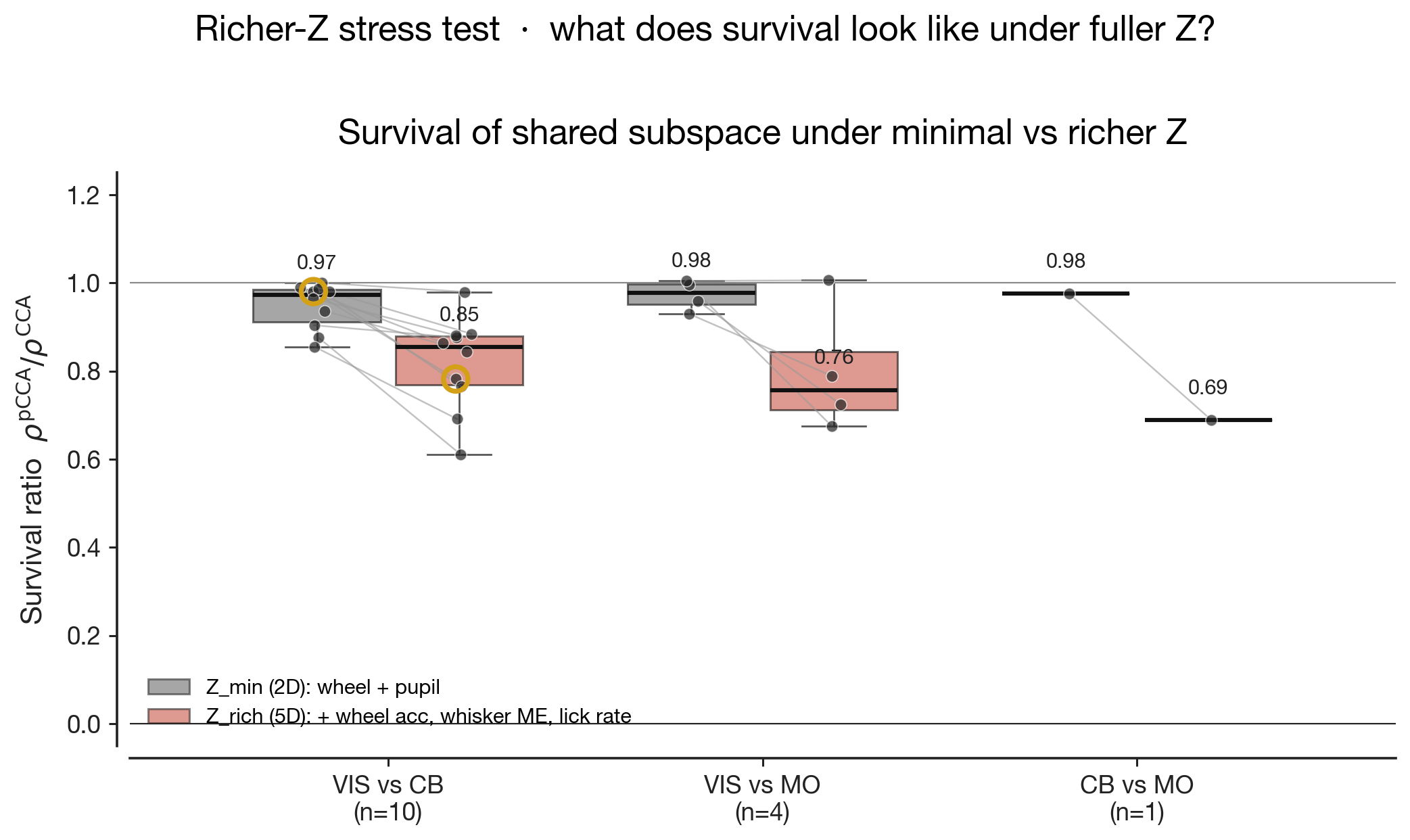
right column shows pCCA under rich-Z partialling — wheel velocity,
wheel acceleration, whisker motion energy, body motion energy, pupil
diameter, and lick rate all linearly removed from each region's
activity before CCA is fit. The cloud shape barely changes
between the two columns — the cross-region canonical
correlation $\rho$ printed in the corner moves by 0.02–0.04 across all
three pairs — yet the wheel gradient collapses to near zero in every
panel. The shared subspace did not collapse, but the wheel-velocity
meaning of position along it did. The geometry persists, stripped of
its behavioural meaning, and what remains must be aligned to something
we have not measured.
How do the regions sort trial conditions? Cross-region RSA
CCA asks whether the two regions share axes. But two regions
can encode the same task structure through completely different axes
and still agree on which conditions are similar to which others.
To probe that basis-free notion of shared geometry, we use
representational similarity analysis (Kriegeskorte et al. 2008).
Every trial gets a condition label combining stimulus side
(L/R), absolute-contrast bin (0,
lo, mi, hi — 0 %,
0–6.25 %, 6.25–25 %, 25–100 %), and feedback outcome
(+ correct, − incorrect) — e.g. Lhi+
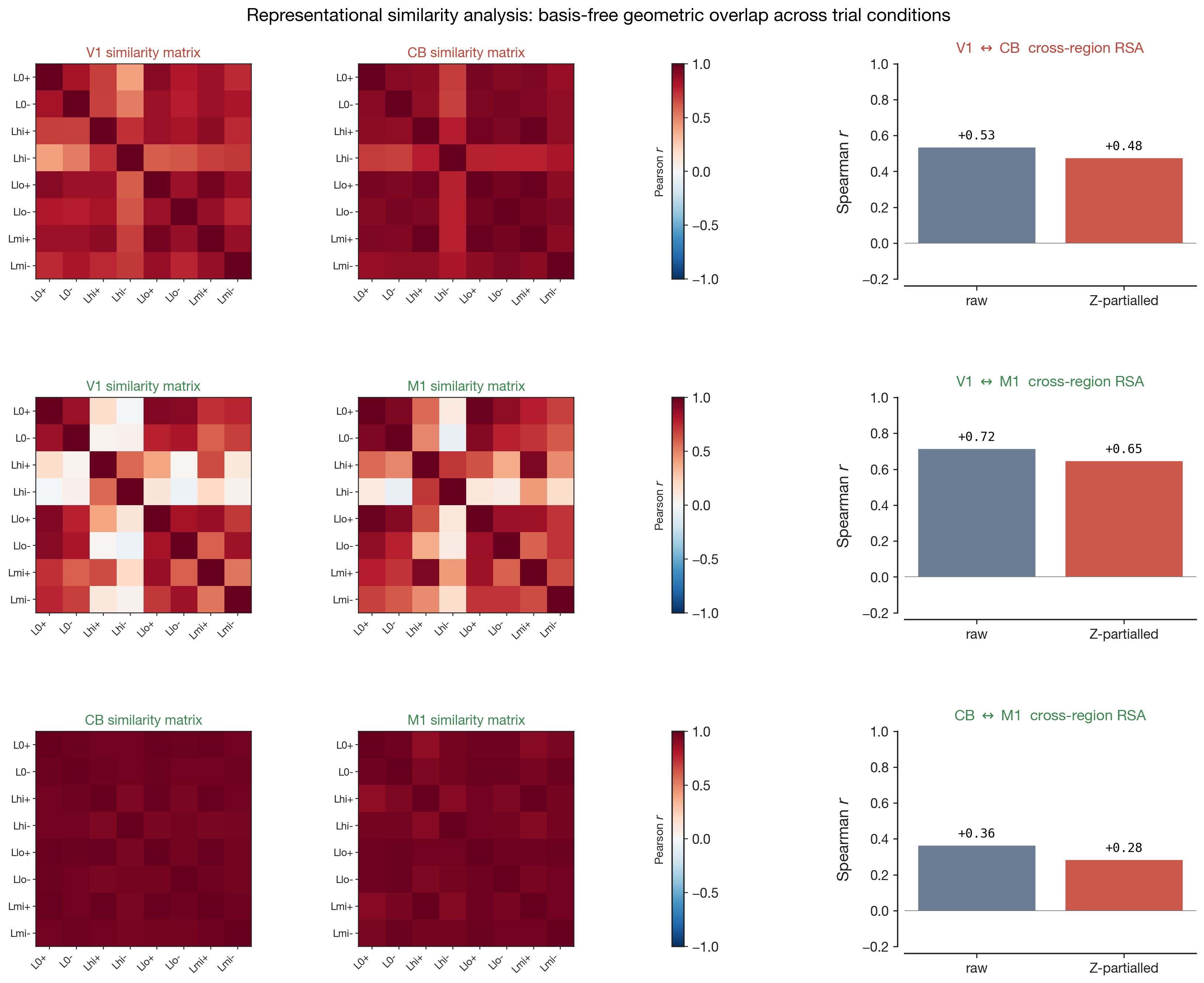
= "high-contrast left, correct". For each condition we average the SVCA
scores over the 400 ms post-stimulus window, then build a per-region
similarity matrix whose rows and columns are both that label
set, in the same order. Cell $(i, j)$ is the Pearson $r$
between the mean activity vectors for conditions $i$ and $j$ — deep red
($r \approx +1$) means "these two conditions evoked very similar
population responses in this region", white ($r \approx 0$) means
"uncorrelated", and deep blue ($r \approx -1$) means "anti-correlated".
Each matrix is symmetric, with $r = 1$ on the diagonal (every condition
is identical to itself), and is the region's geometric fingerprint of how
it groups task conditions. The cross-region overlap is the Spearman
correlation between the corresponding upper triangles of the two
matrices (higher = more shared geometry).
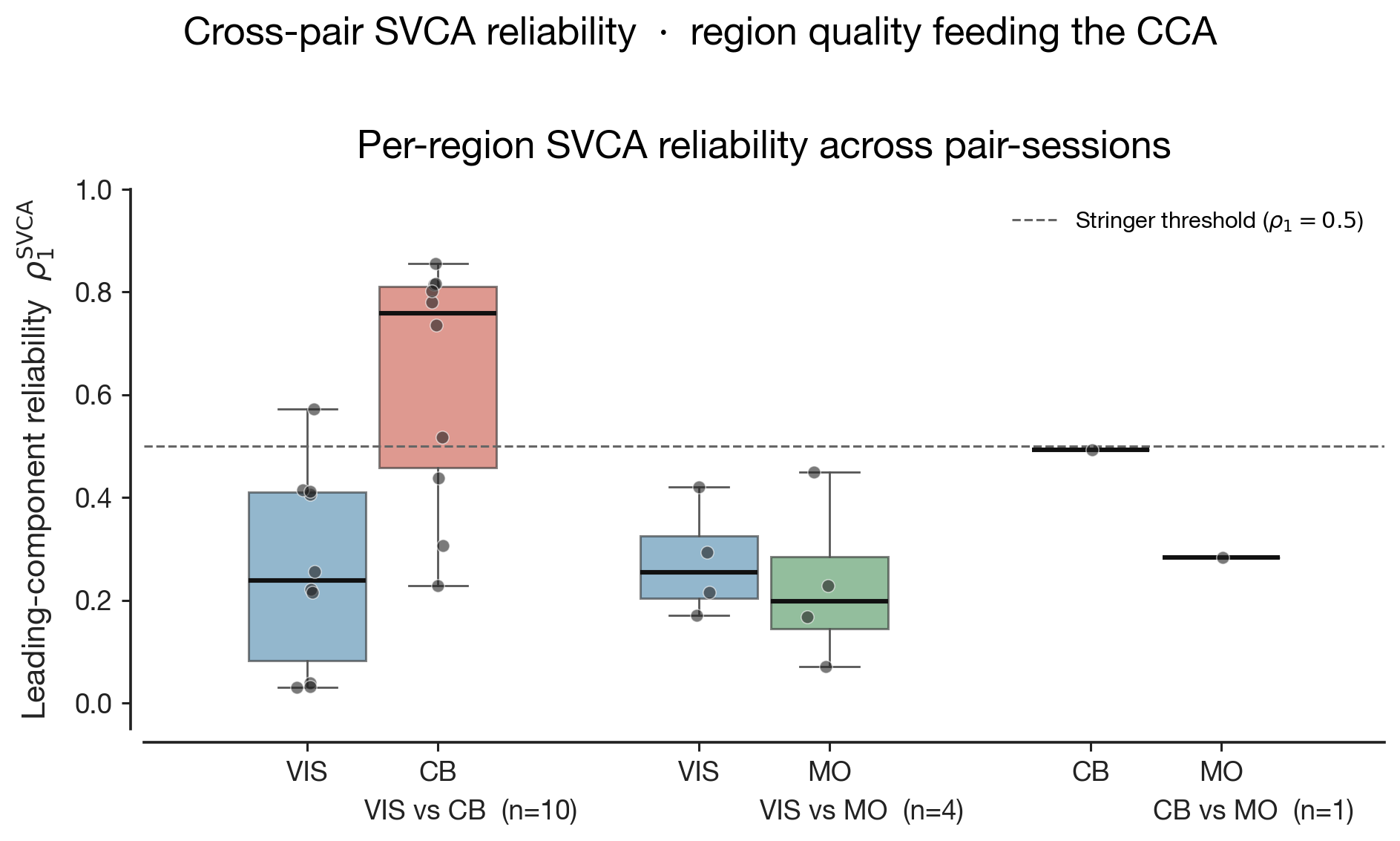
Before reading the cross-region overlap, the within-matrix structure
of each individual similarity matrix tells us how much that single region
cares about the trial labels at all. A uniformly red matrix means the
region treats every condition as evoking essentially the same population
response — it has not committed any of its leading SVCA dimensions to
discriminating side, contrast, or feedback in the post-stimulus window.
Block structure means the region does discriminate, and the
block boundaries reveal which variable it cares about: a 4×4 split along
contrast bins says "this region encodes how bright the stimulus was";
checkerboard alternation along the +/− axis says
"this region encodes whether the mouse got it right". The matrix is not
just an input to the cross-region statistic — it is the per-region
readout of representational specificity.
The three pair-rows do not show this in equal measure. The
V1↔CB row has two near-uniformly red
matrices: in the 400-ms post-stimulus window, neither V1's leading SVCA
modes nor CB's strongly discriminate amongst left-side trial conditions
at the population level — the matrices are featureless, the cross-region
Spearman correlation ($r \approx +0.53$) is therefore measuring overlap
between two relatively flat fingerprints. The
V1↔M1 row is the most informative:
both matrices show clear off-diagonal whitish cells, indicating that
certain condition pairs evoke clearly distinct patterns (e.g. correct
vs incorrect at the same contrast), and the two matrices' patterns
visibly resemble each other — which is why their cross-region Spearman
is the strongest in the dataset ($r \approx +0.72$ raw, $+0.65$
partial) despite V1↔M1 having the smallest leading canonical correlation
of the three pairs. The CB↔M1 row
sits in between on M1's side and again featureless on CB's: the
cerebellum, on this fast post-stimulus window, simply does not sort
these task labels along its reliable SVCA axes, so the cross-region
Spearman ($r \approx +0.36$ raw, $+0.28$ partial) is dragged down by
one region having no condition-specific structure to share.
The take-away is that axis-aligned overlap (CCA) and basis-free
condition-structure overlap (RSA) are not the same thing, and per-pair
they can be ranked in opposite orders. V1↔M1's shared geometry lives in
the pattern of condition similarities more than in
co-rotating axes; CB↔M1's shared geometry lives in fewer real axes
(the directed +40-ms transmission seen in §5) but those axes do not
organise the task-condition structure visibly within our window. The
small drop under partialling in every pair mirrors the CCA finding:
shared condition geometry persists after stripping the behavioural axes.
One number cannot summarise that — two pictures and two metrics can.